Fine-Tuning Instability for Large Language Models
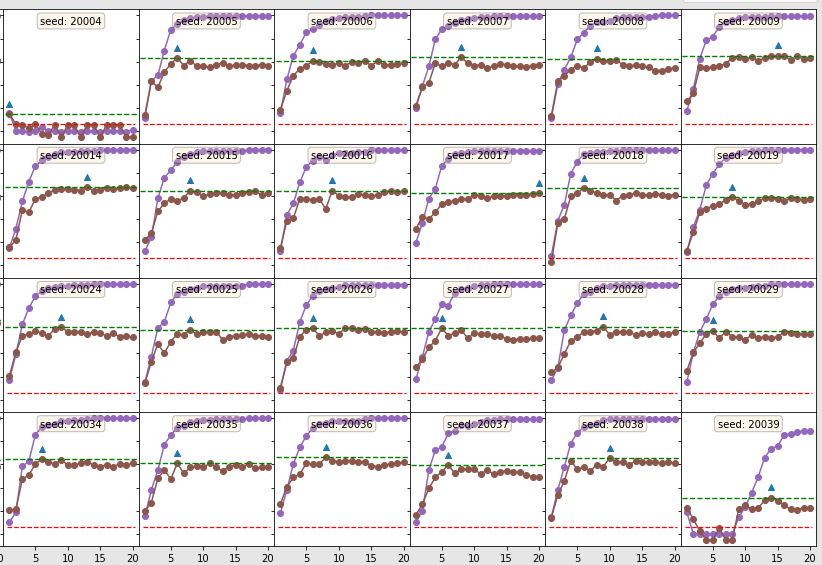
This blog post investigates the current state of instability for fine-tuning large language models (LLMs), and some improvements that have been made since the advent of BERT.
In particular, it is determined that the most serious forms of instability, failed fine-tuning runs and catastrophic forgetting, still remain an issue. An in depth look at \(L^2-\mathrm{SP}\) regularization is taken, a technique claimed to mitigate these.