
Text Classification with the High-Level TensorFlow API
The present post was originally published as a Medium article of the same title: Text Classification with the High-Level TensorFlow API. It is reproduced here so that a Medium membership is not required for access.
Update. The TensorFlow API has changed somewhat since this article was written. Notably the article predates TensorFlow version 2, and uses the outdated version 1.
In this blog post we share our experience, in considerable detail, with using some of the high-level TensorFlow frameworks for a client’s text classification project. These include the Estimator framework and feature columns.
The client had a large and growing database of emails, each of which was to be classified into one class from a fixed set of non-overlapping categories, i.e. multiclass classification. This was subject to the following requirements.
- Use the TensorFlow library.
- Have acceptable classification accuracy (not necessarily optimal).
- The classification model is to be used in production. A trained model must be transferable to a server where it classifies new emails as they arrive.
- The model must be capable of online learning, i.e. the model can update itself as new labeled data becomes available, without retaining the original training data.
- Provide graphical presentations through TensorBoard.
The motivation for the high-level interface is to simplify the task of building machine learning models. It is not necessary to understand the inner workings of the TensorFlow library when using the high-level APIs since they are hidden from the model developer. For example, our included code has no explicit references to Graphs or Sessions. See also the Resources section.
There are a number of other high-level interfaces built on top of TensorFlow, e.g. Keras, but here we just use the new high-level API that is part of TensorFlow itself.
The code presented below was developed with python 3.6 and TensorFlow v1.4, and was also tested on TensorFlow v1.7. The complete code is available at our GitHub repository.
Data
The solution provided to the client was not specific to their data, which happened to be foreign language emails. We use the DBpedia ontology dataset extracted from Wikipedia, described in the preprint arXiv:1509.01626 [cs.LG], for demonstration purposes, but any suitably formatted dataset can be substituted.
All of our example programs will look in the data directory for the
three files train.csv, test.csv and classes.txt, and if they are
not present will automatically download the DBpedia dataset and extract
these files. To use a different dataset, any suitably formatted files
with these respective filenames can be placed in the data directory (you
can simply overwrite the three files if they have already been
extracted).
To see the format of the data:
>>> import pandas as pd
>>> train_raw = pd.read_csv('data/train.csv', header=None)
>>> train_raw[:3]
0 1 2
0 1 E. D. Abbott Ltd Abbott of Farnham E D Abbott Limited w...
1 1 Schwan-Stabilo Schwan-STABILO is a German maker of pe...
2 1 Q-workshop Q-workshop is a Polish company located...
Column 0 is the enumerated value of the ontology class, from 1 to 14, as
listed in the file classes.txt (Company, EducationalInstitution, …);
column 1 is the title of the Wikipedia article; and column 2 is the
Wikipedia abstract which serves as the “document”. In the case where
each entry is an email, the title would be the email subject and the
document would be the full email text. Our model does not use the title
for classification purposes.
For this data we are doing what is known as topic classification (or document classification). We point out that our models can also be used for any kind of NLP task involving binary or multiclass classification (binary of course means there are two classes); for example, for sentiment analysis with positive versus negative sentiment.
The following function from common.py loads the data and preprocesses
it.
The complete code for common.py is provided at the end of the article, including definitions of the called subroutines. These are all straightforward, except for process_vocabulary which is discussed in the next section.
The important thing to note is that after the raw training and test data is loaded, the entries are randomly shuffled (lines 15–20). This is necessary for mini-batch training, at least for the training data. The DBPedia data in train.csv is organized so that all of the data in class 1 is first, then all of the data in class 2, and so on. If mini-batch training is attempted without shuffling then most mini-batches will have all of their examples in the same class, making training futile. On the other hand, for full-batch training there is no need (or advantage) to shuffle.
Another important step is to subtract 1 from the labels, so that they run from 0–13 instead of 1–14. This is done by extract_data (line 21, see the end of the article for the code). It is necessary because, as usual, one-hot encodings begin at 0 in TensorFlow.
Vocabulary Processor
Given text data a typical first step is to parse each of the text documents into words and (possibly discarded) punctuation. This process is called tokenization. Next a vocabulary is enumerated over the training data, which transforms text documents to sequences of integers where each word is mapped to its integer index. These integer sequences are then all made to have the same length max_doc_len by truncating and padding the sequences as needed. This yields the collection of text documents as an integer matrix with dimensions (num_docs, max_doc_len), an object that TensorFlow can handle.
Smaller max_doc_len values result in a smaller matrix that uses less memory and requires less computation, but throws out more of the data. We use a default value of 10 so the programs can run quicker, but this can be changed by a command line argument.
While there are more capable tokenizers, for example in the nltk library, we use the VocabularyProcessor which is included in the TensorFlow API. This class performs the above transformation, from collections of text documents (train_sentences and test_sentences) to integer matrices (train and test), respectively, in the code displayed below.
|
|
For the actual code used in our examples, which also allows for online learning,
see the process_vocabulary function in common.py.
Estimators
These are the highest level objects and heart of the high-level TensorFlow machine learning framework. They are an abstract representation of a machine learning model. The actual model is specified by the model_fn argument of Estimator’s initializer. It is a function that specifies the architecture (i.e. builds a TensorFlow graph) and specifies how to train, evaluate and make predictions.
All of our models use softmax classifiers, and thus their output layers are logits with the same number of nodes as there are classes. Since they all perform training, evaluation and prediction the same way, their respective model_fn arguments first create the model specific architecture and then call the following function in common.py:
estimator_spec_for_softmax_classification specifies the predicted class, that the loss function is cross entropy between the softmax of the logits and the labels, that the AdamOptimizer is used to minimize the loss during training and that the accuracy metric should be used for evaluation.
Models
One of the benefits of the high-level API is that it allows one to more quickly try out a number of models on a given problem. Thus we tried out a few models on the dataset.
Perceptron
We begin with the simplest model, a perceptron. This refers to a feed-forward neural network with a single layer and a softmax output function, rather than a perceptronin the traditional sense consisting of a single neuron with a Heavyside output function. In other words, this is multinomial logistic regression.
The input layer of our perceptron has max_vocab_size nodes in order to allow a one-hot encoding of the integer sequences representing the text documents. The output layer has output_dim nodes, which is the number of classes. It serves as logits for a softmax classifier that chooses the class. It can be described to TensorFlow using feature columns (see the Resources) as follows:
bow_column = tf.feature_column.categorical_column_with_identity(
WORDS_FEATURE, num_buckets=params.n_words)
bow_embedding_column = tf.feature_column.embedding_column(
bow_column, dimension=params.output_dim)
logits = tf.feature_column.input_layer(
features,
feature_columns=[bow_embedding_column])
For the actual code, see the bag_of_words_perceptron model function in the perceptron.py code listing below.
categorical_column_with_identity creates a the one-hot representation of the integer sequences. embedding_column represents bow_column as a real-valued vector with dimension given by the dimension parameter. It does this by adding adding a fully-connected layer with dimension nodes; this maps every integer below max_vocab_size to a real-valued vector, and then embedding_column combines each integer sequence into a single vector by taking the mean.
input_layer creates the tensor logits out of the feature column bow_embedding_column, which gets fed the features. Here, features is a dict with one key WORDS_FEATURE whose value is the integer input matrix of size (num_docs, max_doc_len) (see the Vocabulary Processor section). The net effect of this word to vector embedding is that the input matrix is mapped to a real-valued matrix of size (num_docs, output_dim). Note that while input_layer is usually the initial part of some neural network architecture, in this case it is in fact the output layer.
Since the embedding of each input is calculated as the mean over its words, the word ordering of each document is irrelevant, i.e. this is a bag of words model.
Multilayer Perceptron (MLP)
This refers to a feed-forward neural network with multiple layers. (Calling this a perceptron is a popular misnomer.) Our MLP has two layers, one hidden layer with embed_dim nodes that is fully connected to an output layer with output_dim nodes. The code for its model function is as follows:
The initial part of the model is essentially the same as the perceptron, with a one-hot encoding given to the input layer embedded as an embed_dim dimensional real-valued vector in the hidden layer. The hidden layer is then activated by a ReLU which connects to the output layer.
Recurrent Neural Network (RNN)
This model is a recurrent neural network composed of gated recurrent units (GRUs):
embed_sequence (line 7) creates a word to vector embedding as before; however, sequences of integers are now mapped to sequences of vectors, as this is not a bag of words model. Thus an integer input matrix of size (num_docs, max_doc_len) will get mapped to a tensor of dimension (num_docs, max_doc_len, embed_dim). The tensor word_vectors is then unpacked (line 13) into a sequence of max_doc_len tensors for input to the RNN.
static_rnn creates the RNN of GRU cells (line 21). The RNN model has the additional LENGTHS_FEATURE, which is the length of each document. This allows the RNN to pass the output of the last element of the sequence (i.e. the last word in the document) straight to the output layer. Since each sequence is padded with zeros, we could make do without this (i.e. no sequence_length parameter). However, this is suboptimal and in fact without lengths, and with max_doc_len set to 200, the model was unable to learn anything, which we would guess is due to vanishing gradients. (See also the section Test Runs.)
Training and Evaluation
Estimators should be all that is needed for training and evaluating these models on a single machine. However, at least when we were testing things out with TensorFlow v1.4, we were not able to get precisely the desired behaviour using the Estimator class methods. We ended up using the Experiment class to train and evaluate the models, even though Experiment is intended for distributed computing. This does not significantly complicate the code, and it gives us the control we desire.
The Experiment takes an Estimator in its initializer (line 45), and the parameters train_input_fn and eval_input_fn are functions that describe the input processing for training and evaluation, respectively. In both cases, we call input_fn (line 1) which takes advantage of the high-level function tf.estimator.inputs.numpy_input_fn to create the actual input functions from our specifications, since we are feeding numpy objects x and y to the model. The Estimator methods for training and evaluation also take an input function as a parameter, as we see in the inference example (see query.py below). In this way, the high-level API decouples the input processing from the core model, and makes it much easier than with the usual low-level API to swap inputs, as we do for inference below.
We use the tf.contrib.learn_runner.run function to do the training and/or evaluation (line 57). It takes a function as the first parameter which constructs the Experiment that is used for this purpose.
Executables
These were developed with a GPU enabled TensorFlow installation. Without GPU, these programs could take over an hour to run with default settings. If running on a CPU, you may want to set the n-epochs argument to 1, as explained below.
1. perceptron.py
This is a program that simply trains and evaluates the perceptron model:
To run the program with the default settings, as with any python script:
$ python perceptron.py
Since the program is intended for python 3, python should of course be replaced with python3 if you also have python 2 in your environment. The initial output is:
Preprocessing data...
Successfully downloaded dbpedia_csv.tar.gz 68431223 bytes.
The longest sentence in the training data has 1472 words.
Size of training set: 560000
Size of test set: 70000
Number of words in vocabulary: 822383
Elapsed: 77.46 s
Training model for 2 epochs...
All of our executables take command line arguments, which are described with the
-h flag. For example,
$ python perceptron.py -h
shows the optional settings and default values for perceptron.py. Any of our models can be trained further by running the corresponding executable again, with the same model directory (can be set with --model-dir). Running a second time will skip the somewhat time consuming vocabulary processing step, since the results are already saved to disk.
Conversely, if you want to retrain a model from scratch you should delete the model directory before running the program. For example, if the max_doc_len setting is changed you should retrain a fresh model.
By default, our programs print out a lot of info from TensorFlow, but there is a --verbosity setting. To train the perceptron model for one more epoch, and just check progress on TensorBoard:
$ python perceptron.py --n-epochs 1 --verbosity warn
With regards to TensorBoard, the Estimator automatically logs information to TensorBoard. The default model directory for perceptron.py is perceptron_model, so that we can launch TensorBoard with
$ tensorboard --logdir perceptron_model
Here are some statistics in the SCALARS tab after the first run of perceptron.py:
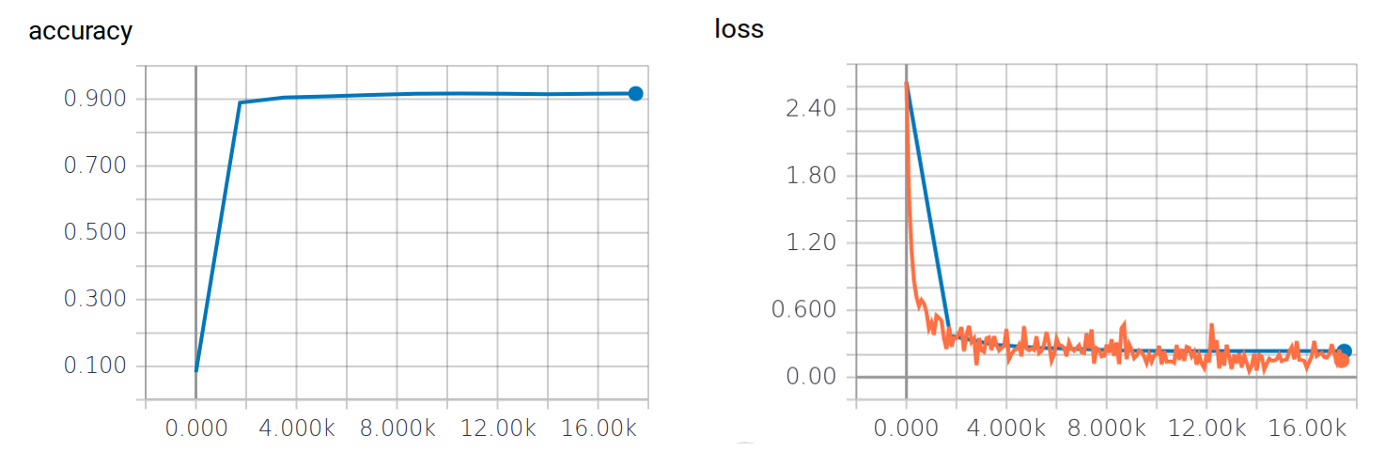
Accuracy and Loss versus training step on training (orange) and evaluation (blue) sets
Full-batch learning
The models can be trained with full-batch learning by setting the batch-size parameter to full, for example:
$ python perceptron.py --batch-size full --n-epochs 100
However, as is well-known it is inefficient to make each update with the redundant full training set, and it uses excessive memory. In fact, running the above command with GPU enabled TensorFlow gave us an out of memory error. We also found the the resulting model less accurate than with mini-batch learning.
2. query.py
This script performs inference on a trained model. This covers requirement 3 of the client, that the model can make classifications on new data, perhaps on a different computer system. The following code query.py reads a list of sentences from a file (queries.txt by default) and classifies them with the specified model:
Suppose that we trained the perceptron model using defaults, so that the model directory is perceptron_model. Then the example queries can be run by
$ python query.py perceptron_model perceptron --verbosity warn
The second argument specifies the model, and can also be mlp or rnn. The output we get is:
Number of words in vocabulary: 822383
The model classifies "University of Toronto" as a member of the class EducationalInstitution.
The model classifies "TTC: Toronto Transit Commission, run buses, streetcars and subways" as a member of the class Company.
The model classifies "Dragon" as a member of the class Artist.
The model classifies "Harley Davidson" as a member of the class Artist.
The model classifies "A kitten is a baby cat." as a member of the class Company.
The model classifies "Dog sleds are sleds pulled by a number of dogs on harnesses. They were used by the Eskimos." as a member of the class WrittenWork.
The model classifies "Bering Strait" as a member of the class NaturalPlace.
The model classifies "Whitehorse, Yukon" as a member of the class Artist.
The model classifies "Marijuana, also called hemp or cannabis" as a member of the class Plant.
The model classifies "Bat Out of Hell by Meat Loaf" as a member of the class Album.
We chose 10 examples from the set of categories, pretty much “at random”. As we can see, the model classified 5 out of 10 queries correctly. The poor performance is presumably because Wikipedia abstracts are much more informative than our example descriptions.
The model can be moved to another system for inference by copying the model directory to some directory on the server. This can be tested with query.py by specifying the new directory:
$ python query.py new-directory perceptron
The reason this is so simple is because the high-level Estimator class saves to and restores from the model directory automatically, whereas this must be done manually with the low-level API. There is also the TensorFlow Serving project for providing inference on a trained model as a service, but that is beyond the scope of this article.
We can also do inference on a saved checkpoint of the model. For example, when we trained a model with mlp.py (see below) using the default settings and then queried the model, only 4 out of 10 queries were correctly classified. However, an earlier checkpoint of the model with a slightly better evaluation performed better:
$ python query.py mlp_model mlp --checkpoint 10501
gives the output:
Number of words in vocabulary: 822383
INFO:tensorflow:Using config: {'_task_type': None, '_task_id': 0, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x7f8aef38bef0>, '_master': '', '_num_ps_replicas': 0, '_num_worker_replicas': 0, '_environment': 'local', '_is_chief': True, '_evaluation_master': '', '_tf_config': gpu_options {
per_process_gpu_memory_fraction: 1.0
}
, '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_secs': 600, '_log_step_count_steps': 100, '_session_config': None, '_save_checkpoints_steps': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_model_dir': 'mlp_model/'}
INFO:tensorflow:Restoring parameters from mlp_model/model.ckpt-10501
The model classifies "University of Toronto" as a member of the class EducationalInstitution.
The model classifies "TTC: Toronto Transit Commission, run buses, streetcars and subways" as a member of the class Company.
The model classifies "Dragon" as a member of the class MeanOfTransportation.
The model classifies "Harley Davidson" as a member of the class Artist.
The model classifies "A kitten is a baby cat." as a member of the class Company.
The model classifies "Dog sleds are sleds pulled by a number of dogs on harnesses. They were used by the Eskimos." as a member of the class WrittenWork.
The model classifies "Bering Strait" as a member of the class NaturalPlace.
The model classifies "Whitehorse, Yukon" as a member of the class Company.
The model classifies "Marijuana, also called hemp or cannabis" as a member of the class Plant.
The model classifies "Bat Out of Hell by Meat Loaf" as a member of the class Album.
with 5 out of 10 queries correctly classified.
3. perceptron_example.py
This is an example of online learning with the perceptron model, as in requirement 4 of the client. In order to demonstrate online learning, the training and test set are both split in half. The perceptron model is then trained and evaluated on the first split. Online learning is the ability to further train a model on some new previously unseen data, without keeping the original data and training again with the new and old data combined. Thus the program further trains and evaluates the model on the second split, without using the first split.
Since the high-level API decouples the input from the core model, additional training with new data is straightforward as we can see from the code listing:
The only difficulty is that the new training data contains new vocabulary, and the model vocabulary should be extended to include these to be effective. Since the input to the neural network is a one-hot encoding of the vocabulary, it must contain enough nodes to accommodate the all of the vocabulary to ever be included in the model. The number of nodes is set with the --max-vocab-size argument which defaults to 1000000. If it is set smaller than the vocabulary size, the program will crash.
Also notice the parameter extend=True to process_vocabulary (line 62), which indicates that the passed-in vocab_processor should be extended.
The above code example also shows how to evaluate the model performance on the training set (see line 74), e.g. useful for estimating removable bias. This outputs:
INFO:tensorflow:Saving dict for global step 17500: accuracy = 0.9573, global_step = 17500, loss = 0.123623855
The results of the evaluation can also be viewed on TensorBoard.
4. mlp.py
This program trains and evaluates our multilayer perceptron model. It also demonstrates visualization of the word embedding in TensorBoard. Since the code for the MLP model was already displayed above, we only show the function that runs the Experiment (please visit the repository for the full code listing):
In addition to training and evaluating the MLP model, we see that metadata is created and associated with the learned word embedding for display on TensorBoard (lines 19–30). create_metatdata writes the file word_metadata.tsv which contains one word of our vocabulary on each line, in the order of the word indexing (see common.py below or on GitHub for the code).
Running TensorBoard and looking at the PROJECTOR tab we can visualize the word embedding learning by this model:
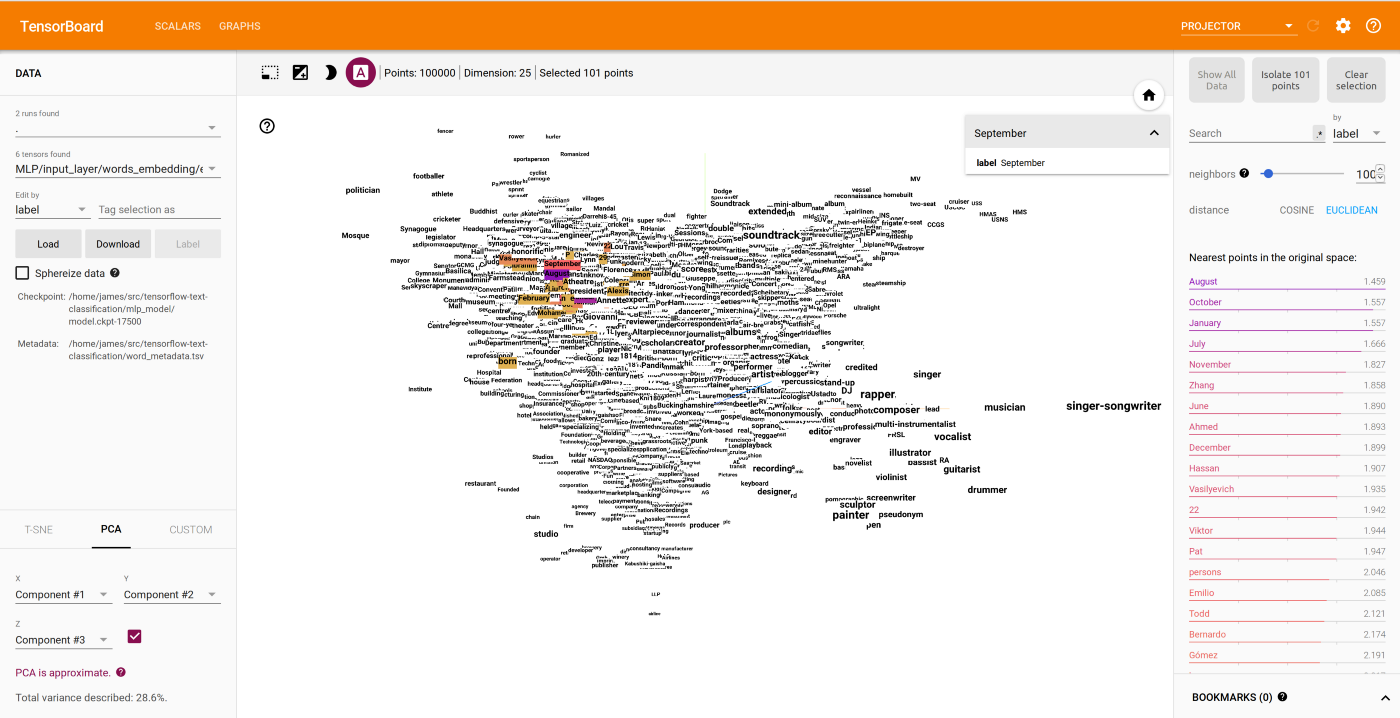
3D PCA projection of 25-dimensional word embedding and words nearest to ‘September’
In version of the code written in the low-level TensorFlow API we also visualized the embeddings of the entire documents into 25-dimensional space (where each document is mapped to the mean of its word embeddings), which was interesting because we could view the separation between different classes. However, we were unable to get this working using only the high-level API.
5. rnn.py
The trains and evaluates the recurrent neural network model. The code is similar to perceptron.py (and is available from the repository). The key difference is that we also obtain the length of each document from process_data. This is passed to run_experiment:
|
|
which inputs the lengths to the model as a feature.
Test Runs
These models have room for improvement. For example, we could add regularization by dropouts or batch normalization, etc… Nonetheless, we naturally wanted to see what kind of results we could get with the programs we made.
For the perceptron, we found that increasing the number of words used from each document, i.e. max_doc_len, improved model performance but slowed down the learning. Our best model was obtained by including all words by setting max_doc_len = 1472 (the longest document) and using the following parameters:
$ python perceptron.py --max-doc-len 1472 --batch-size 64 --learning-rate 0.1 --n-epochs 25
This achieved 98.4% accuracy on the fifth saved checkpoint:
INFO:tensorflow:Validation (step 211751): accuracy = 0.98384285, loss = 0.067757286, global_step = 211751
The MLP model behaves differently. Beyond some point, increasing max-doc-len decreases model performance. On the other hand, this point increases as the embedding dimension increases, and a higher max-doc-len is needed to get good performance with higher embedding dimension. Our best MLP model was obtained with:
$ python mlp.py --max-doc-len 75 --embed-dim 50 --batch-size 16 --learning-rate 0.003 --n-epochs 2
and did somewhat better than the perceptron in terms of loss, with 98.5% accuracy:
INFO:tensorflow:Saving dict for global step 70000: accuracy = 0.98471427, global_step = 70000, loss = 0.05893088
The RNN model behaves similarly to MLP with regards to max_doc_len and embed_dim, but now max_doc_len can be viewed as the depth of the neural network and as such we faced memory constraints. Our best RNN model performed much better than the MLP, which is to be expected since this model takes into account the word ordering:
$ python rnn.py --max-doc-len 125 --embed-dim 50 --batch-size 16 --n-epochs 1
It achieved 98.9% accuracy:
INFO:tensorflow:Saving dict for global step 35001: accuracy = 0.98884284, global_step = 35001, loss = 0.04099217
It is also perhaps interesting that while our best perceptron and MLP models did very poorly on the example queries — try for example:
$ python query.py mlp_model mlp --max-doc-len 75 --embed-dim 50 --verbosity warn
the best RNN did comparatively well — try:
$ python query.py rnn_model rnn --max-doc-len 125 --embed-dim 50 --verbosity warn